ELF 文件格式理解
我对 ELF(Executable and Linking Format) 文件的感觉可以用“熟悉”而“陌生”来形容,在工作中每天都会用到,但从来没有真正理解过它的定义。为了满足自己的好奇心,决定用博客的形式来记录学习可重定位目标文件、可执行目标文件以及共享目标文件的整个过程。文章并不会包含完整的文档定义,相应的文档会放在参考资料列表中。
可重定位目标文件
ELF 格式可以大致分为图中两种视图,左边为连接视图,右边为运行视图:

在这个章节中只涉及到左边的视图,从连接视图中可以看到可重定位目标文件的结构大致可以分为 ELF Header、Sections 以及 Section Header Table 三个部分。
我直接以 MIT 6.828 实验一中的 boot.o 作为实际例子:
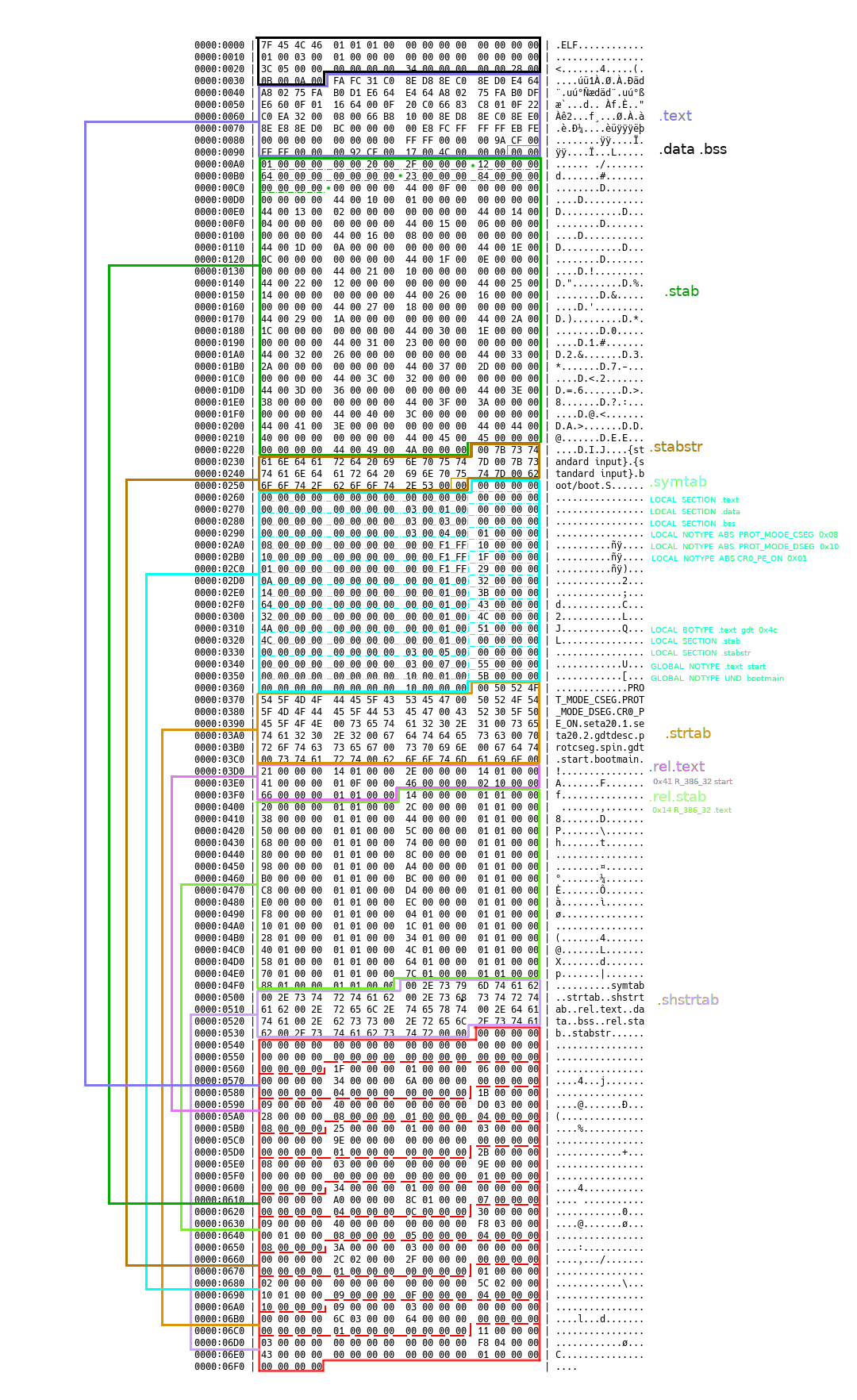
ELF Header
黑色框选中的部分就是连接视图中的 ELF Header 部分,主要包含以下字段:
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
}e_ident 是一个长度为16个字节的数组,这个数组包含了文件的基本标识信息:
/*
0000:0000 | 7F 45 4C 46 01 01 01 00 00 00 00 00 00 00 00 00
*/
EI_MAG0 0x7f 前4个字节为 ELF 文件标识,为固定值
EI_MAG1 'E'
EI_MAG2 'L'
EI_MAG3 'F'
EI_CLASS 0x01 32位
EI_DATA 0x01 字节流为小端
EI_VERSION 0x01 版本默认为 1
EI_PAD 0x00 后面字节均为补零基于32位和字节流相关信息就可以将剩余的字节和 ELF Header 中的其他字段一一对应起来:
/*
0000:0010 | 01 00 03 00 01 00 00 00 00 00 00 00 00 00 00 00
0000:0020 | 3C 05 00 00 00 00 00 00 34 00 00 00 00 00 28 00
0000:0030 | 0B 00 0A 00
*/
e_type; 0x0001 //文件类型为可重定位文件
e_machine; 0x0003 //架构为 EM_386(Inter Architecute)
e_version; 0x00000001 //文件版本号
e_entry; 0x00000000 //执行入口,连接视图先忽略
e_phoff; 0x00000000 //Program header table 的字节偏移量
e_shoff; 0x0000053C //Section header table 的字节偏移量
e_flags; 0x00000000 //处理器特定标志位
e_ehsize; 0x0034 //ELF Header 长度,52个字节
e_phentsize; 0x0000 //Program header 长度
e_phnum; 0x0000 //Program header 数量
e_shentsize; 0x0028 //Section header 长度,40个字节
e_shnum; 0x000B //Section header 数量,11个 Section header
e_shstrndx; 0x000A //shstrtab 在 Section header table 中的索引值Section Header
从 ELF Header 中的 e_shoff、e_shentsize 和 _e_shnum 字段可以获得 Section header table 的起始位置、每个 Section 的字节长度和 Section 的数量。boot.o 实例图片中最下方红色边框中的就是 Section header table 的所有内容。
/*
0000:0530 | 00 00 00 00
0000:0540 | 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000:0550 | 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0000:0560 | 00 00 00 00 1F 00 00 00 01 00 00 00 06 00 00 00
0000:0570 | 00 00 00 00 34 00 00 00 6A 00 00 00 00 00 00 00
0000:0580 | 00 00 00 00 04 00 00 00 00 00 00 00 1B 00 00 00
...
0000:06C0 | 00 00 00 00 01 00 00 00 00 00 00 00 11 00 00 00
0000:06D0 | 03 00 00 00 00 00 00 00 00 00 00 00 F8 04 00 00
0000:06E0 | 43 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00
0000:06F0 | 00 00 00 00
*/Section header table 中总有包含11(0x0B)个 Section header,第一个 Section header 从 0x053C 的字节处开始,所有字段均为0,这相当于默认节。Section header 的结构如下所示:
typedef struct {
Elf32_Word sh_name;
Elf32_Word sh_type;
Elf32_Word sh_flags;
Elf32_Addr sh_addr;
Elf32_Off sh_offset;
Elf32_Word sh_size;
Elf32_Word sh_link;
Elf32_Word sh_info;
Elf32_Word sh_addralign;
Elf32_Word sh_entsize;
} Elf32_Shdr;ELF Header 最后一个字段 e_shstrndx 指向 Section header table 中一个特别的 Section header,也就是 .shstrtab 的 Section header,位于 Section header table 的最后一项。这里就用它来解释 Section header 结构中各个字段的含义。
/*
0000:06C0 | 11 00 00 00
0000:06D0 | 03 00 00 00 00 00 00 00 00 00 00 00 F8 04 00 00
0000:06E0 | 43 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00
0000:06F0 | 00 00 00 00
*/
sh_name 0x00000011 //Section 名称的索引值
sh_type 0x00000003 //Section 类型为 SHT_STRTAB
sh_flags 0x00000000 //Section flags 为未定义
sh_addr 0x00000000 //Section 在进程中的内存地址
sh_offset 0x000004F8 //Section 在文件中的字节偏移量
sh_size 0x00000043 //Section 字节长度
sh_link 0x00000000 //SHN_UNDEF
sh_info 0x00000000 //没有拓展信息
sh_addralign 0x00000001 //没有对齐约束
sh_entsize 0x00000000 //条目大小(字节)sh_type 为 SHT_STRTAB 说明对应 Section 的内容为字符串信息,事实上这个 Section 包含所有 Section 的名称信息,这部分会在说明 Section 部分时详细说明。
通过 Section header table 中各个 Section header 的 sh_offset 和 sh_size 字段,我们可以定位 ELF 文件中的所有 Section 位置,完成示例图片中那样完整的字节范围划分。
Sections
Section 分为很多不同的类型,这里先关注一下最简单类型:SHT_STRTAB。从它的名称可以看出,这个 Section 中包含的就是普通的字符串。以前面提到的 .shstrtab 的内容为例:
index 0 1 2 3 4 5 6 7 8 9
+---+---+---+---+---+---+---+-------+---+
0 |\0 | . | s | y | m | t | a | b |\0 | . |
+---------------------------------------+
10 | s | t | r | t | a | b |\0 | . | s | h |
+---------------------------------------+
20 | s | t | r | t | a | b |\0 | . | r | e |
+---------------------------------------+
30 | l | . | t | e | x | t |\0 | . | d | a |
+---------------------------------------+
40 | t | a |\0 | . | b | s | s |\0 | . | r |
+---------------------------------------+
50 | e | l | . | s | t | a | b |\0 | . | s |
+---------------------------------------+
60 | t | a | b | s | t | r |\0 | | | |
+---+---+---+---+---+---+---+---+---+---+所有字符串都以 \0 为分隔符,中间部分为 Section 的名称。比如最后一个 Section header 的 sh_name 为 0x00000011,即十进制的 17,对应上面表格中第2行第7列的 . 开始,一直到第3行第5列的 b 结束,内容为 .shstrtab。
所有 Section header 中 sh_name 对应的名称为:
Section 0 0x00000000 00 \0 //为空
Section 1 0x0000001F 31 .text
Section 2 0x0000001B 27 .rel.text
Section 3 0x00000025 37 .data
Section 4 0x0000002B 43 .bss
Section 5 0x00000034 52 .stab
Section 6 0x00000030 48 .rel.stab
Section 7 0x0000003A 58 .stabstr
Section 8 0x00000001 01 .symtab
Section 9 0x00000009 09 .strtab
Section 10 0x00000011 17 .shstrtab到这里已经可以知道文件中各个 Section 中存放的数据内容了,.text、.data 以及 .bss 分别存放了程序的可执行代码、已初始化的数据和未初始化的数据。.stab、.rel.stab 和 .stabstr 保存的是 debug 相关的信息,这里暂且忽略。
.rel.text 保存了 .text 节中在连接是需要重定位的所有条目。正常来说 .data 也可能会有 .rel.data 与之对应,但由于示例目标文件在 .data 并未引用其他文件变量,所以没有包含对应节。
.symtab 就是常说的符号表,.strtab 保存了所有符号(symbol)的字符串名称。符号表保存了所有在目标文件中定义或者被引用的符号条目。比如在目标文件中定义的全局或静态变量,引用的函数等等。符号表条目的结构定义如下:
typedef struct {
Elf32_Word st_name;
Elf32_Addr st_value;
Elf32_Word st_size;
unsigned char st_info;
unsigned char st_other;
Elf32_Half st_shndx;
} Elf32_Sym;一个符号条目需要占用16个字节的长度,因此 boot.o 示例图中的 .symtab 是一个包含17个条目的数组,并且索引为0的条目默认所有字段均为0,也就是说一共包含16个有效的符号条目。这里选择几个不同的符号条目说明相关字段的含义。
索引为4的条目字段解释如下:
/*
0000:0290 | .. .. .. .. .. .. .. .. .. .. .. .. 01 00 00 00
0000:02A0 | 08 00 00 00 00 00 00 00 00 00 F1 FF .. .. .. ..
*/
st_name 0x00000001 //在 .strtab 中的索引值,即 "PROT_MODE_CSEG"
st_value 0x00000008 //受 st_shndx 影响,值为 0x08
st_size 0x00000000 //条目大小,这里为0个字节
st_info 0x00 //前4位为条目绑定域,0 为 STB_LOCAL
//后4位为条目类系,0 为 STT_NOTYPE
st_other 0x00 //保留字段,无意义
st_shndx 0xFFF1 //SHN_ABS,st_value 为绝对值索引为15的条目字段解释如下:
/*
0000:0340 | .. .. .. .. .. .. .. .. .. .. .. .. 55 00 00 00
0000:0350 | 00 00 00 00 00 00 00 00 10 00 01 00 .. .. .. ..
*/
st_name 0x00000055 //在 .strtab 中的索引值,即 "start"
st_value 0x00000000 //于 .text 节起始位置的偏移量
st_size 0x00000000 //条目大小,这里为0个字节
st_info 0x10 //前4位为条目绑定域,1 为 STB_GLOBAL
//后4位为条目类系,0 为 STT_NOTYPE
st_other 0x00 //保留字段,无意义
st_shndx 0x0001 //所属节的索引,索引1为 .text索引为16的条目字段解释如下:
/*
0000:0350 | .. .. .. .. .. .. .. .. .. .. .. .. 5B 00 00 00
0000:0360 | 00 00 00 00 00 00 00 00 10 00 00 00 .. .. .. ..
*/
st_name 0x0000005B //在 .strtab 中的索引值,即 "bootmain"
st_value 0x00000000 //未定义
st_size 0x00000000 //条目大小,这里为0个字节
st_info 0x10 //前4位为条目绑定域,1 为 STB_GLOBAL
//后4位为条目类系,0 为 STT_NOTYPE
st_other 0x00 //保留字段,无意义
st_shndx 0x0000 //SHN_UNDEF,引用自其他文件最后还需要了解一下 Section header 2 所对应的 Section .rel.text,从名称可以看出这是一个 SHT_REL 类型的节,即重定向节,里面包含的是 .text 需要的重定位条目信息。sh_entsize 值为 0x08,那么在 .rel.text 中一共包含5个重定位条目。条目的结构如下:
typedef struct {
Elf32_Addr r_offset; //需要重定位的位置偏移量
Elf32_Word r_info; //前24位为符号表索引,后8位为条目类型
} Elf32_Rel;.rel.text 节的所有内容可以解释为:
/*
0000:03D0 | 21 00 00 00 14 01 00 00 2E 00 00 00 14 01 00 00
0000:03E0 | 41 00 00 00 01 0F 00 00 46 00 00 00 02 10 00 00
0000:03F0 | 66 00 00 00 01 01 00 00 .. .. .. .. .. .. .. ..
*/
OFFSET TYPE VALUE
00000021 R_386_16 .text
0000002e R_386_16 .text
00000041 R_386_32 start
00000046 R_386_PC32 bootmain
00000066 R_386_32 .text不同的重定位条目类型在连接可执行文件时有不同的地址计算方法,这个后面在细说。现在先关注一下 r_offset 的含义。可以看到 bootmain 对应的 r_offset 值为 0x00000046,类型为 R_386_PC32,也就是说明在连接时连接器需要修改 .text 起始地址偏移 0x46 个字节的处的4个字节的值为运行时地址。
/*
0000:0030 | FA FC 31 C0 8E D8 8E C0 8E D0 E4 64
0000:0040 | A8 02 75 FA B0 D1 E6 64 E4 64 A8 02 75 FA B0 DF
0000:0050 | E6 60 0F 01 16 64 00 0F 20 C0 66 83 C8 01 0F 22
0000:0060 | C0 EA 32 00 08 00 66 B8 10 00 8E D8 8E C0 8E E0
0000:0070 | .. .. .. .. .. .. .. .. .. E8 FC FF FF FF .. ..
0000:0080 | 00 00 00 00 00 00 00 00 FF FF 00 00 00 9A CF 00
0000:0090 | FF FF 00 00 00 92 CF 00 17 00 4C 00 00 00 00 00
*/
//反汇编代码
45: e8 fc ff ff ff call 46 <protcseg+0x14>
46: R_386_PC32 bootmain.text 所有内容如上所示,从 0x34 开始偏移 0x46 的位置为 0x7B 开始的4个字节: 0xFFFFFFFFC。从反汇编代码可以看到 0xFFFFFFFFC 应该是函数 bootmain 的运行时地址,但是由于可重定位目标文件并不知道程序在运行时的真正地址,因此现在只能看到一个相对位置,在连接时会将这4个字节会被修改为真正的有效地址。
可执行目标文件
在大致了解了可重定位目标文件的结构后再看可执行目标文件就会容易很多。下面将从运行视图的角度来学习可执行目标文件的结构。
这里使用一个非常简单的程序作为新的结构示例,为了保证可执行目标文件的体积,使用了汇编代码 :
;tiny.asm
;nasm -f elf tiny.asm
;gcc -Wall -m32 -nostdlib -no-pie tiny.o -o tiny
;./tiny ;echo $?
BITS 32
SECTION .data
words db "Hello, World!", 0
len equ $ - words
SECTION .bss
age resd 1
SECTION .text
GLOBAL _start
_start:
mov eax,1
mov ebx, 42
int 0x80逻辑相当于 C 程序:
#define len 14
char words[] = "Hello, World!";
int age;
int
main(void)
{
return 42;
}从代码可以看出这个程序什么都没有做,只是在 .data 段中定义了 words 变量,然后在 .bss 段定义了一个未初始化的变量 age。.text 程序段只是简单的返回了42,仅此而已。下面是它的 ELF 结构图:

前面已经介绍过的 Section Header Table 等部分只是大致标注了范围,不再多做说明,现在主要关注具有彩色边框的字节块。
ELF Header
黑色边框部分的 ELF Header 的结构和可重定位目标文件一样,只是之前被忽略的部分字段现在有了意义。我用”*“号把需要关注的字段都做了标注:
/*
0000:0010 | 02 00 03 00 01 00 00 00 C0 80 04 08 34 00 00 00
0000:0020 | 1C 02 00 00 00 00 00 00 34 00 20 00 03 00 28 00
0000:0030 | 08 00 07 00
*/
e_type; 0x0002 //*文件类型为可执行目标文件
e_machine; 0x0003 // 架构为 EM_386(Inter Architecute)
e_version; 0x00000001 // 文件版本号
e_entry; 0x080480C0 //*执行入口
e_phoff; 0x00000034 //*Program header table 的字节偏移量
e_shoff; 0x0000021C // Section header table 的字节偏移量
e_flags; 0x00000000 // 处理器特定标志位
e_ehsize; 0x0034 // ELF Header 长度,52个字节
e_phentsize; 0x0020 //*Program header 长度,32个字节
e_phnum; 0x0003 //*Program header 数量,3个
e_shentsize; 0x0028 // Section header 长度,40个字节
e_shnum; 0x0008 // Section header 数量,8个
e_shstrndx; 0x0007 // shstrtab 在 Section header table 中的索引值文件类型变成 ET_EXEC,表明这是一个可执行的目标文件。e_entry 字段不再是零值,现在是程序执行时的虚拟内存地址。还多了一个包含3个 Program header 的 Program header table。
Program Header
从 ELF Header 的 e_phoff、e_phentsize 和 e_phnum 可以知道 Program header table 的起始地址为 0x34,包含3个 Program header,每个长度为32个字节。大致的划分范围可以查看示例图中红色边框的部分。
Program header 的字段结构定义如下:
typedef struct {
Elf32_Word p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
Elf32_Addr p_paddr;
Elf32_Word p_filesz;
Elf32_Word p_memsz;
Elf32_Word p_flags;
Elf32_Word p_align;
} Elf32_Phdr;具体的含义如下:
/*
0000:0030 | .. .. .. .. 01 00 00 00 00 00 00 00 00 80 04 08
0000:0040 | 00 80 04 08 CC 00 00 00 CC 00 00 00 05 00 00 00
0000:0050 | 00 10 00 00 .. .. .. .. .. .. .. .. .. .. .. ..
*/
p_type 0x00000001 //类型为 PT_LOAD,运行时目标段要加载到内存
p_offset 0x00000000 //段相对于文件开始处的偏移地址
p_vaddr 0x08048000 //段的虚拟内存地址
p_paddr 0x08048000 //段的物理内存地址
p_filesz 0x000000CC //段在文件中的字节长度
p_memsz 0x000000CC //段在内存中的字节长度
p_flags 0x00000005 //权限标识位,0x05=PF_R|PF_X,可读可执行
p_align 0x00001000 //段在内存中的对齐方式,4096,即4k
/*
0000:0050 | .. .. .. .. 01 00 00 00 CC 00 00 00 CC 90 04 08
0000:0060 | CC 90 04 08 0E 00 00 00 14 00 00 00 06 00 00 00
0000:0070 | 00 10 00 00 .. .. .. .. .. .. .. .. .. .. .. ..
*/
p_type 0x00000001 //类型为 PT_LOAD,运行时目标段要加载到内存
p_offset 0x000000CC //段相对于文件开始处的偏移地址
p_vaddr 0x080490CC //段的虚拟内存地址
p_paddr 0x080490CC //段的物理内存地址
p_filesz 0x0000000E //段在文件中的字节长度
p_memsz 0x00000014 //段在内存中的字节长度
p_flags 0x00000006 //权限标识位,0x06=PF_R|PF_W,可读可写
p_align 0x00001000 //段在内存中的对齐方式,4096,即4k
/*
0000:0070 | .. .. .. .. 04 00 00 00 94 00 00 00 94 80 04 08
0000:0080 | 94 80 04 08 24 00 00 00 24 00 00 00 04 00 00 00
0000:0090 | 04 00 00 00 .. .. .. .. .. .. .. .. .. .. .. ..
*/
p_type 0x00000004 //类型为 PT_NOTE,附加信息,可忽略
p_offset 0x00000094 //段相对于文件开始处的偏移地址
p_vaddr 0x08048094 //段的虚拟内存地址
p_paddr 0x08048094 //段的物理内存地址
p_filesz 0x00000024 //段在文件中的字节长度
p_memsz 0x00000024 //段在内存中的字节长度
p_flags 0x00000004 //权限标识位,0x04=PF_R,可读
p_align 0x00000004 //段在内存中的对齐方式,4,即4字节Segments
第一个 Program header 对应的段包含了文件 0x00 - 0xcc 的所有字节,对应于示例图中绿色边框部分,包含了 ELF Header、Program header table、.note 和 .text,这就是传说中的只读储存器段(代码段)。
第二个 Program header 对应了从 0xcc - 0xda 中的 .data 和 .bss 数据段(棕色边框部分),从 p_flags 可以看出这个段是可读可写的。这里需要注意的是 p_filesz 和 p_memsz 的值是不同的,p_memsz 多出了6个字节。这是因为 .bss 中定义的变量所需要的字节在文件中是没有分配的,加载到内存中是就必须分配对应的内存空间了。多出的六个字节可以理解为:
char words[14]; //14个字节
char pad[2]; //2个字节
int age; //4个字节第三个 Program header 对应的段保存了兼容性检查之类的附加信息,这里就不详细说明其结构了,有兴趣的可以直接查看参考资料里的文档资料。
可执行目标文件中的各个段描述了程序运行时在内存中的状态:
